Stroke Width Transform
Tue, Nov 17, 2015Optical character recognition (OCR) works well on clean images, but poorly on noisy ones. The Stroke Width Transform is a technique used to extract text from a noisy image, such as a photo, by isolating shapes that share a consistent stroke width. The resulting image eliminates most of the noise but preserves text, and produces more reliable OCR results.
How it Works
SWT attempts to identify strokes inside the given image - these are elements of finite width, bounded by two roughly parallel edges, as you would see with a pen stroke on a page. Strokes are the dominant element in written and typed characters, but are relatively rare elsewhere.
The transform starts by identifying high contrast edges in the image. By traversing the image in the direction orthogonal to the edge, we can look for a parallel edge that indicates we’ve found a stroke.
Connecting adjacent stroke cross-sections with similar widths yields each complete stroke. A contiguous stroke typically represents a man-made character, since most natural or otherwise noisy shapes don’t exhibit stroke-like characteristics, and those that do usually don’t possess consistent stroke width.
The characters can be filtered, grouped (into words), and superimposed into a final output image without any knowledge of the language or font type of the text. This clean image is then much easier for OCR to process.
An OpenCV Implementation with Python
Inspired by @aperrau’s DetectText project, I wanted to play with this solution in Python. To get things rolling, I installed OpenCV with homebrew, set up a virtual environment, and symlinked the new OpenCV modules into my environment. Note that I’m using Python 2.7 and OpenCV 2.4.12 here on OSX:
$ brew tap homebrew/science
$ brew install opencv
$ virtualenv env
$ cd env/lib/python2.7/site-packages
$ ln -s /usr/local/Cellar/opencv/2.4.12/lib/python2.7/site-packages/cv.py cv.so
$ ln -s /usr/local/Cellar/opencv/2.4.12/lib/python2.7/site-packages/cv2.so cv2.so
Alternately, I’ve created a docker container that contains the whole setup, hosted on github:
docker pull bunn/docker-opencv
docker run -i -t bunn/docker-opencv bash
I have a basic (but slow and disorganized) prototype of SWT implemented at github.com/mypetyak/StrokeWidthTransform.
Step by Step
My implementation of SWT operates in a few steps:
Use the OpenCV library to extract image edges using Canny edge detection
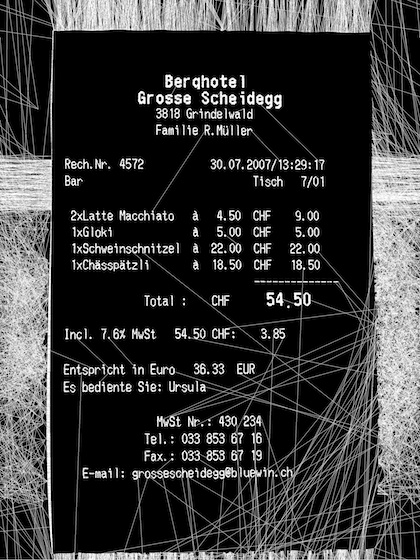
Original:

Source: https://commons.wikimedia.org/wiki/File:ReceiptSwiss.jpgEdges:

Calculate the x- and y-derivatives of the image, which can be superimposed to yield the image gradient. The gradient describes, for each pixel, the direction of greatest contrast. In the case of an edge pixel, this is synonymous with the vector normal to the edge.
x-derivative:

y-derivative:

For each edge pixel, traverse in the direction θ of the gradient until the next edge pixel is encountered (or you fall off the image). If the corresponding edge pixel’s gradient is pointed in the opposite direction (θ - π), we know the newly-encountered edge is roughly parallel to the first, and we have just cut a slice through a stroke. Record the stroke width, in pixels, and assign this value to all pixels on the slice we just traversed.
For pixels that may belong to multiple lines, reconcile differences in those line widths by assigning all pixels the median stroke width value. This allows the two strokes you might encounter in an ‘L’ shape (depending on the beginning edge pixel) to be considered with the same, most common, stroke width.
Connect lines that overlap using a union-find data structure, resulting in a disjoint set of all overlapping stroke slices. Each set of lines is likely a single letter/character.
An example line set:

Another set:

Apply some intelligent filtering to the line sets; we should eliminate anything too small (width, height) to be a legible character, as well as anything too long or fat (width:height ratio), or too sparse (diameter:stroke width ratio) to realistically be a character.
Use a k-d tree to find pairings of similarly-stroked shapes (based on stroke width), and intersect this with pairings of similarly-sized shapes (based on height/width). Calculate the angle of the text between each pair of characters.
Use a k-d tree to find pairings of letter pairings with similar orientations. These groupings of letters likely form a word. Chain similar pairs together.

Produce a final image containing the resulting words.
{kind=link}
Improvements
I’m still working on two major areas of improvement: As you can see in the above output, there are some funky long artifacts that need to be resolved. The image traversal can also be greatly improved with some work replacing nested iteration with more advanced matrix algebra.